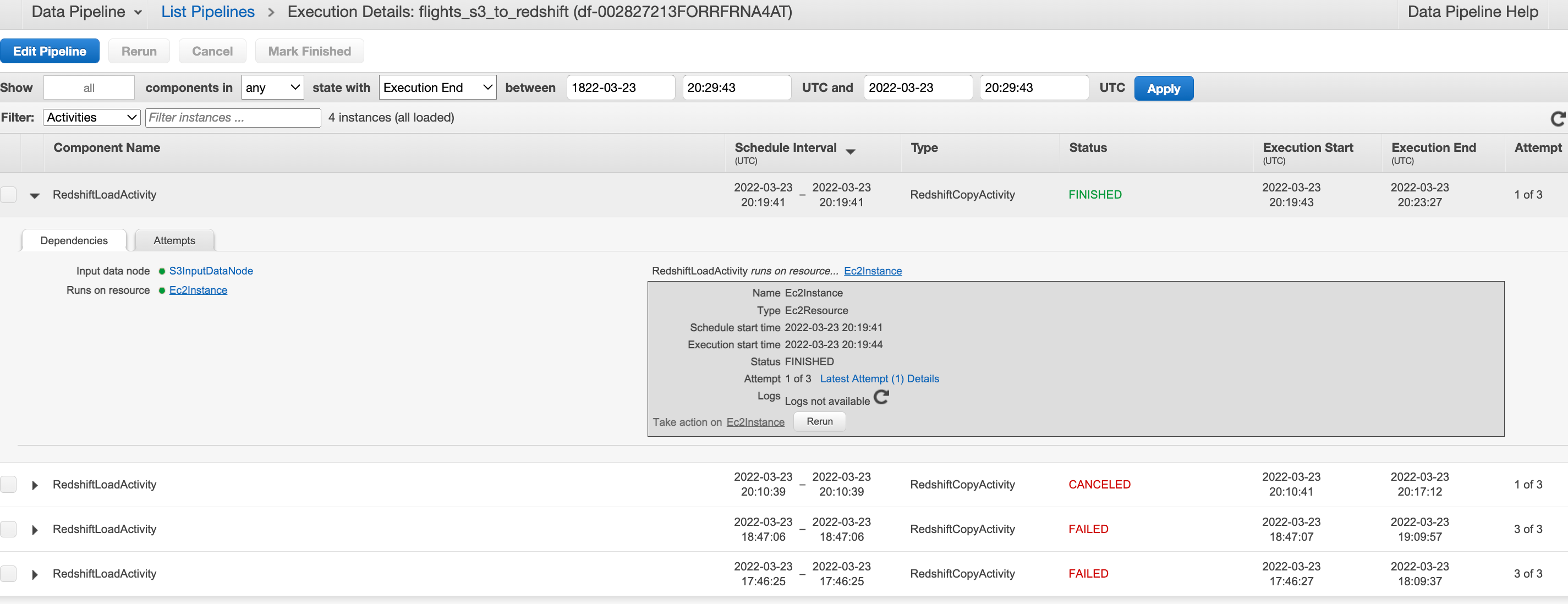
Data Pipeline S3 to Redshift
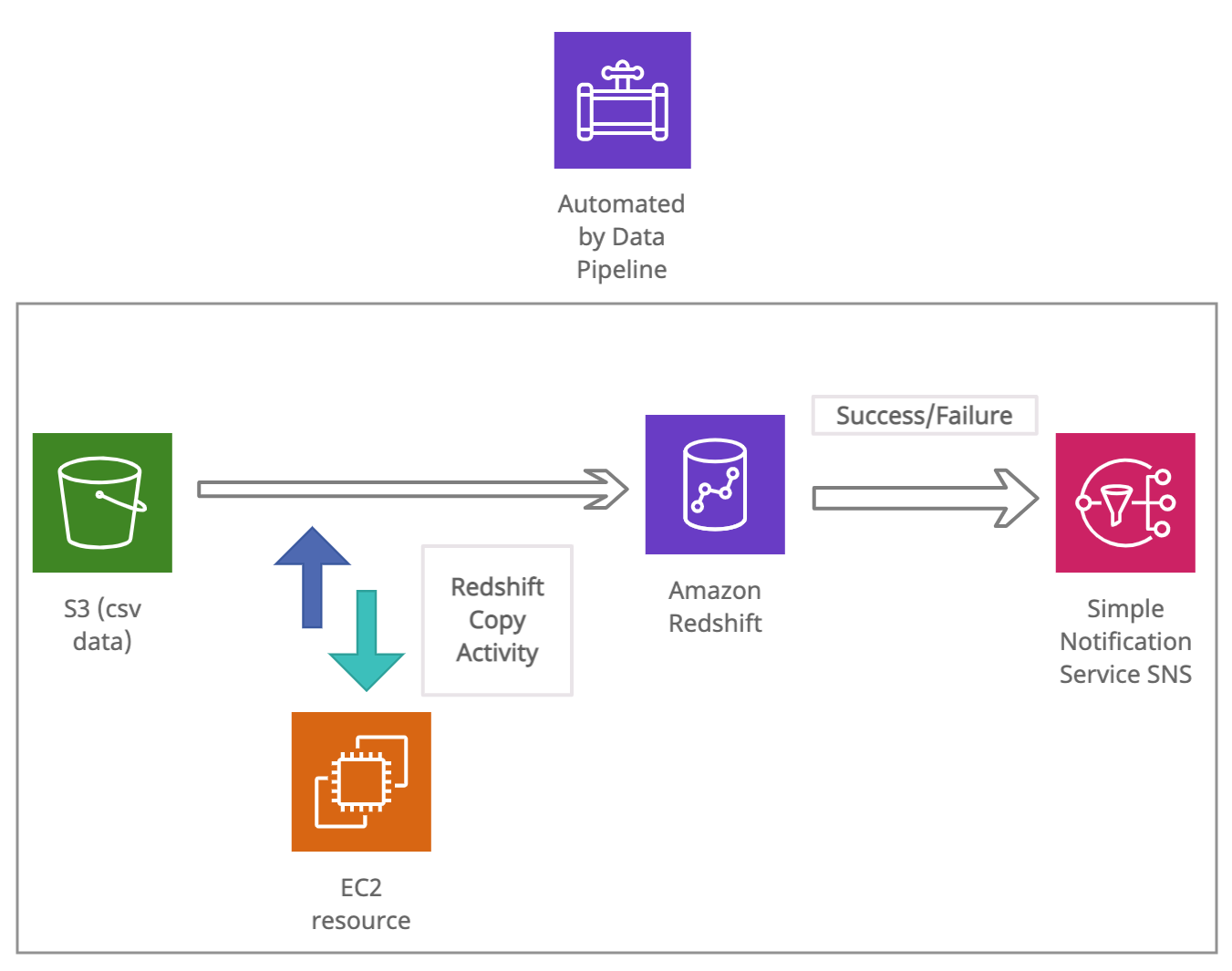
We have the datasets/delays.csv loaded in S3 bucket and we will use data pipeline to automate copying of this data into table in redshift cluster. To do this we first need to create and activate a redshift cluster
Creating redshift cluster
We can create a cluster ‘redshift-cluster’ with 2 nodes and default db ‘dev’ Also need to pass a list IAM roles that can be used by the cluster to access other Amazon Web Services services. Optionally can also pass vpc security groups to be associated with the cluster
aws redshift create-cluster --node-type dc2.large \
--number-of-nodes 1 \
--master-username user \
--master-user-password password \
--dbname dev \
--cluster-identifier redshift-cluster \
---iam-roles [<arn>/AWSServiceRoleForRedshift, <arn>/myspectrum_role]
--vpc-security-group-ids [sg-0f3936c13c90c635e, sg-2f8ca355]
--cluster-subnet-group-name default
Creating and updating pipeline definition
To create your pipeline definition and activate your pipeline, use the following create-pipeline command.
aws datapipeline create-pipeline --name flights_s3_to_redshift --unique-id token
{
"pipelineId": "df-002827213FORRFRNA4AT"
}
You can verify that your pipeline appears in the pipeline list using the following list-pipelines command.
$ aws datapipeline list-pipelines
{
"pipelineIdList": [
{
"id": "df-04133292K3OYT6A9KW89",
"name": "s3_to_dynamodb"
},
{
"id": "df-002827213FORRFRNA4AT",
"name": "flights_s3_to_redshift"
}
]
}
To upload your pipeline definition, use the following put-pipeline-definition command, with the pipeline id output from the commands above. The pipeline definition config json file is stored in data-pipelines/config/s3_to_redshift.json (this can also be generated once pipeline is created, using the get-pipeline-definition command
aws datapipeline put-pipeline-definition --pipeline-id df-002827213FORRFRNA4AT \
--pipeline-definition file://data-pipelines/config/s3_to_redshift.json
{
"validationErrors": [],
"validationWarnings": [],
"errored": false
}
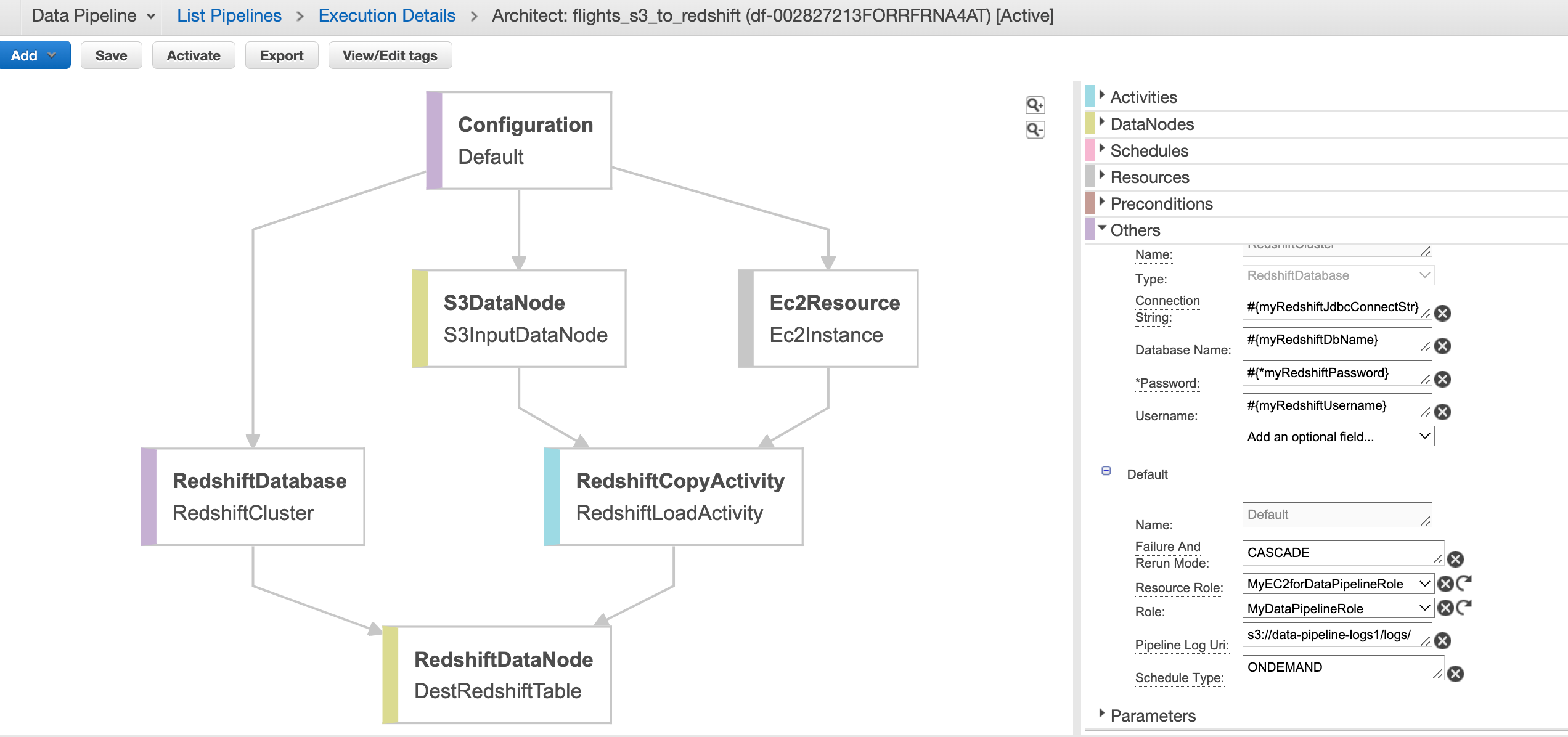
Activating pipeline and monitoring
To activate your pipeline, use the following activate-pipeline command.
aws datapipeline activate-pipeline --pipeline-id df-002827213FORRFRNA4AT
Monitor the pipeline run on the console or from the data pipeline logs folder in S3. These are partitioned by pipeline-id –> Activity_Type —-> Runtime —> Attempt_number e.g≥