
AWS Glue is a serverless ETL service that makes it simple and cost-effective to clean and transform data and move it between various data sources and streams. It consists of a metadata repository, AWS Glue Data Catalog AWS Glue consists of a central metadata repository known as the AWS Glue Data Catalog for storing metadata about data sources, transforms, and target. AWS Glue also lets you set up crawlers that can scan data in all kinds of repositories, classify it, extract schema information from it, and store the metadata automatically in the AWS Glue Data Catalog.
Using the metadata in the Data Catalog, AWS Glue can then automatically generate Scala or PySpark scripts with AWS Glue extensions that can be modified to perform various ETL operations. For example, you can extract, clean, and transform raw data in S3 in csv format, and then store the result in parquet format in S3 or into a relational form in Amazon Redshift. AWS Glue introduces the concept of a DynamicFrame. A DynamicFrame is similar to a DataFrame, except that each record is self-describing, so no schema is required initially. Any schema inconsistencies can be resolved to make the dataset compatible with the data store that requires a fixed schema. You can convert DynamicFrames to and from Pyspark DataFrames after you resolve any schema inconsistencies.
In the example below we will configure a Glue crawler to crawl metadata from csv file in S3 and store in Glue Data Catalog. The raw data stored in S3 is free to download from the Bureau of Transportation Statistics and dates all the way back to January 1995 through January 2019. We will then run a glue job script to transform the data and store it in parquet format in S3.
Transforming data in S3 csv and storing as parquet
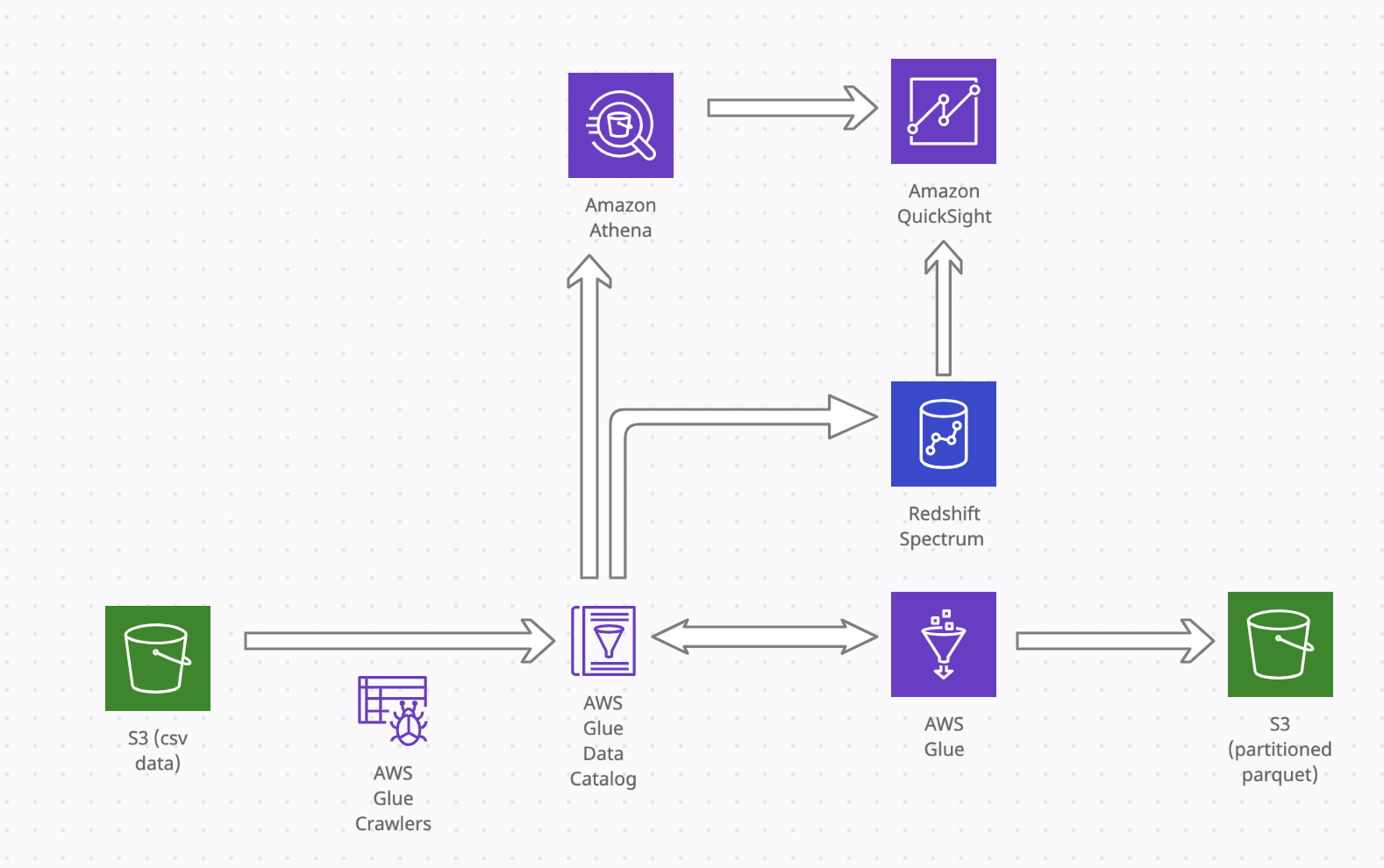
First need to create a database in the glue catalog to store the raw and transformed table schemas. Ive called this flights_summary. The raw CSV files in S3 bucket are crawled using populate the schema and data in the glue data catalog which can be queried with athena. (reference https://docs.aws.amazon.com/glue/latest/ug/tutorial-add-crawler.html) The properties of crawler created can be accessed via console cli as below. The path to the raw csv data “s3://flight-delays-2008/delays”, has been provided, “DatabaseName”: “flights_summary” (created in glue data catalog) Note: So that athena can query tables successfully:
- The path to csv should only include the path upto parent folder csv is in
- There should not be multiple csv in a given folder (no issue for crawler as it will create separate tables in catalog but athena will not like it when querying)
aws glue get-crawler --name flights

For this case, Ive created a customm classifer “header-detect-csv” with the col names and types for the table in catalog as the crawler can sometimes have issues with detecting the column names correctly on its own.

When the crawler is run successfully, we should see a table in the catalog called delays, which can be queried through athena.If you are running athena for the first time, its best to create a workgroup with the necessary IAM permissions and bucket to store the query logs and results before you can run a query.

In the query editor, we can then see the top 10 rows of the table ‘delays’ in the ‘flights_summary’ db in the AWS data catalog

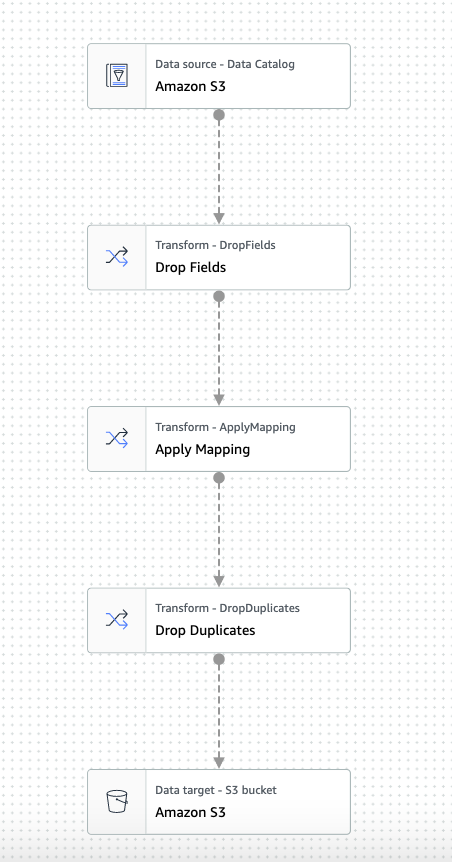
We can now create a glue job for the ETL which uses the catalog table ‘delays’ as source, performs a few transformation steps (.e.g drop fields, cast types and drop duplicate fields) and finally loads to S3 in parquet format (which can be partitioned by specified key). Some handy instructions here https://docs.aws.amazon.com/glue/latest/dg/start-console-overview.html
If building the workflow from glue studio, it automatically generates pyspark code as in glue_etl/script.py. We can use this for debugging purposes if we need to experiment with some custom transforms. this can be done by setting up a development endpoint https://docs.aws.amazon.com/glue/latest/dg/start-development-endpoint.html and attaching sagemaker notebook to the endpoint.
We can also ask glue to create/update another table in catalog with transformed schema and data or do this later via another crawler from parquet results in the bucket. The transformed data can be accessed by athena for querying and visualised via Quicksight.
The job run can be monitored in the job runs in the console or for the logs and error outputs from cloudwatch log group streams.

Once the job is finished we should see the final table in the catalog

We can also use Redshift spectrum to copy external table in redshift from catalog and query in there if required (see sample queries in create_external_tables.sql)
References
- https://docs.aws.amazon.com/athena/latest/ug/tables-location-format.html
- https://aws.amazon.com/premiumsupport/knowledge-center/athena-empty-results/
Pyspark Transforms and Extensions
The script running the glue job is automatically generated from the console via the visual interface. The script first initialises a glue context which wraps the Apache Spark SparkContext object, and thereby provides mechanisms for interacting with the Apache Spark platform. We then create a glue job and pass in job name and parameters which are set in the job configuration in the console.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
from awsglue.dynamicframe import DynamicFrame
from pyspark.sql import functions as SqlFuncs
args = getResolvedOptions(sys.argv, ["JOB_NAME"])
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
job.init(args["JOB_NAME"], args)
We create a dynamic data frame with the glue data catalog as source (passing in database and table name).
1
2
3
4
5
AmazonS3_node1648261615433 = glueContext.create_dynamic_frame.from_catalog(
database="default",
table_name="delays",
transformation_ctx="AmazonS3_node1648261615433",
)
AWS Glue provides a set of built-in transforms which operate on Dynamic DataFrames. Here we use the DropFields to drop the required fields and pass the resultant dynamic dataframe to the ApplyMapping transform. This maps the source columns and data types to target columns and data types in a returned DynamicFrame. Here we can rename any column names or change types if required.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
DropFields_node1648261622521 = DropFields.apply(
frame=AmazonS3_node1648261615433,
paths=[
"'year'",
"'deptime'",
"'dayofweek'",
"'crsdeptime'",
"'arrtime'",
"'crsarrtime'",
"'flightnum'",
"'tailnum'",
"'crselapsedtime'",
"'airtime'",
"'arrdelay'",
"'depdelay'",
"'taxiin'",
"'taxiout'",
"'cancelled'",
"'cancellationcode'",
],
transformation_ctx="DropFields_node1648261622521",
)
# Script generated for node Apply Mapping
ApplyMapping_node1648261643881 = ApplyMapping.apply(
frame=DropFields_node1648261622521,
mappings=[
("'month'", "long", "'month'", "long"),
("'dayofmonth'", "long", "'dayofmonth'", "long"),
("'uniquecarrier'", "string", "'uniquecarrier'", "string"),
("'actualelapsedtime'", "long", "'actualelapsedtime'", "long"),
("'origin'", "string", "'origin'", "string"),
("'dest'", "string", "'dest'", "string"),
("'distance'", "long", "'distance'", "long"),
("'diverted'", "long", "'diverted'", "long"),
("'carrierdelay'", "long", "'carrierdelay'", "long"),
("'weatherdelay'", "long", "'weatherdelay'", "long"),
("'nasdelay'", "long", "'nasdelay'", "long"),
("'securitydelay'", "long", "'securitydelay'", "long"),
("'lateaircraftdelay'", "long", "'lateaircraftdelay'", "long"),
],
transformation_ctx="ApplyMapping_node1648261643881",
)
We then convert the dynamic dataframe to pyspark dataframe and call the pyspark dataframe dropDuplicates API to return a pyspark dataframe with duplicate rows removed. We then create a dynamic dataframe from this pyspark dataframe.
1
2
3
4
5
6
# Script generated for node Drop Duplicates
DropDuplicates_node1648261649257 = DynamicFrame.fromDF(
ApplyMapping_node1648261643881.toDF().dropDuplicates(),
glueContext,
"DropDuplicates_node1648261649257",
)
The final step is to set a S3 destination sink by specifying an S3 path to write the data to and to paritition the data by month. We also update the glue data catalog (without having to re-run the crawler), by passing in enableUpdateCatalog and partitionKeys in getSink(), and call setCatalogInfo() on the DataSink object. This will create new catalog table, with modified schema and add partitions. We then set the format to glueparquet to utilise the AWS Glue optimized parquet writer for DynamicFrames, and finally write the dataframe.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
AmazonS3_node1648261656864 = glueContext.getSink(
path="s3://flight-delays-2008/output_glue_etl/",
connection_type="s3",
updateBehavior="UPDATE_IN_DATABASE",
partitionKeys=["'month'"],
compression="gzip",
enableUpdateCatalog=True,
transformation_ctx="AmazonS3_node1648261656864",
)
AmazonS3_node1648261656864.setCatalogInfo(
catalogDatabase="default", catalogTableName="fl_delays_with_codes"
)
AmazonS3_node1648261656864.setFormat("glueparquet")
AmazonS3_node1648261656864.writeFrame(DropDuplicates_node1648261649257)
job.commit()
You will also notice that we have job.init() in the beginning of the glue script and the job.commit() in the end of the glue script. These two functions are used to initialize the bookmark service and update the state change to the service.
The next blog, will demonstrate how this entire workflow of crawling data and running Glue ETL job can be automated via execution of workflow of states and transitions defined in AWS Step Functions.
Comments powered by Disqus.