
AWS Data Pipeline is a service that helps automate movement of data between different AWS compute and storage services such as Amazon S3, Amazon RDS, Amazon DynamoDB, and Amazon EMR. This helps create complex data processing workloads that are fault tolerant, repeatable, and highly available.
We will create different data pipelines for automating the movement and transformation of data between different AWS services. In each pipeline, you define pipeline objects, such as activities, schedules, data nodes, and resources. This is described in AWS docs
DataPipeline contains three main components
- Pipeline json definition file for specifying the objects as described here
- Pipeline for scheduling the tasks and creating EC2 instances/EMR for running the tasks
- Task Runner automatically installed on resources created which polls and performs the tasks
In all these examples, the data pipeline scheduling has been set to ondemandand requires manual triggering. However, we could also schedule a cron job to run from specific start to end at desired frequency as shown in the examples here
For the next few sections, all references to the script paths will be relative to the following repository root
s3 to RDS

Before running this data pipeline, we need to create an S3 bucket and copy the following objects into it
- datasets/sample-data.csv
- bash script -
data-pipelines/s3_to_rds/psql-copy-s3-rds.sh
The bash script runs the copy command for copying the csv data into rds postgres database via psql. It runs this in an EC2 resource (which is configured via data pipeline configuration) and installs the neccessary packages/libraires such as postgresql13 for using the psql. The bash script takes in keyword args for the jdbc string, username, password and table name as shown in the command below. These are configured via the script arguments setting in the shell command activity in datapipeline task configuration. A special thanks to this resource for helping me generate a working version of this script for my use case !
1
2
$ cd data-pipelines/s3_to_rds
$ sh psql-copy-s3-rds.sh --red_jdbc=<jdbcstring> --red_usr=<Username> --red_pwd=<Password> --red_tbl=<TableName>
The bash script data-pipelines/s3_to_rds/create-pipeline.sh will create the pipeline with the configuration and activate it After cd into root of the repo, run the command below. The first arg is the name of the pipeline to be created and the second arg is the relative path to the defintion json. The placeholder values for the jdbcconnstring, username and password in the json definition would need to be replaced before running the script. Alternatively, these could be modifed in the console once the pipeline is created and then activated.
1
2
3
4
5
6
7
8
9
10
11
12
$ sh data-pipeline/create_pipeline.sh S3-RDS-datapipeline s3_to_rds/postgres-definition.json
Creating data pipeline S3-RDS-datapipeline and activating ...
Adding config settings from json definition for pipeline id df-04865961XZQ7LL0G3TRX
{
"validationErrors": [],
"validationWarnings": [],
"errored": false
}
Activating pipeline df-04865961XZQ7LL0G3TRX
Alternatively we can use the cloudformation template cloudformation/datapipeline/s3-to-rds-postgres.yaml to create a The AWS::DataPipeline::Pipeline resourcewith all the parameter and pipeline objects, such as activities, schedules, data nodes, and resources.https://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/aws-resource-datapipeline-pipeline.html The jdbcstring should be in the format jdbc:postgresql://<endpoint>.rds.amazonaws.com:<port>/<dbname> Replace the <username> and <password> with the username and password for the RDS db created.
1
2
3
4
5
6
aws cloudformation create-stack --stack-name DataPipelineS3toRDS \
--template-body file://cloudformation/datapipeline/s3-to-rds-postgres.yaml \
--parameters ParameterKey=myRDSjdbcstring,ParameterValue=<myRDSjdbcstrin> \
ParameterKey=myRDSUsername,ParameterValue=<username> \
ParameterKey=myRDSPassword,ParameterValue=<password>
Once the stack is created successfully, the pipeline is automatically activated.

We can check the design of the pipeline and the task dependencies if we click on the pipeline id in the console and select edit pipeline. We can see that in this configuration, we have a RDSPOstgresTableCreateActivity (Sql Activity) and CopyS3DatatoEC2 (ShellCommandActivity) which run on an EC2 resource (t1.micro. Amazon Linux AMI)
The TableCreateActivity requires a database reference (RDSPostgres JDBC Database type) which contains the parameters such as connection string, DB username, password, table name etc required to connect to the database and run the sql query for creating the persons table with the required schema. Note that this only creates a table if it does not already exist. So in subsequent commands it will not do so unless the table is manually deleted. The bash script which runs in the subsequent task to truncate data in any existing table from previous data pipeline runs so the table will only have the latest copy of data from the csv file in S3.
The CopyS3DatatoEC2 script installs aws-cli and runs the aws s3 cp command via the cli to copy the csv file from the S3 bucket into path in EC2 resource so it can be later copied into RDS postgres in a subsequent task. This is done - as I am not sure RDS postgres supports copying data directly from S3 to db so needs to be staged into EC2 location first and then copy command run afterwards.
The final activity is the CopyDatatoRDS (ShellCommandActivity) which has parameters for ScriptURi and ScriptArguments configured to run the script psql-copy-s3-rds.sh copied to S3 previously with the required arguments. This installs the necessary dependencies and first truncates the table (in case there is existing data in it) and then runs the copy command to copy data from csv file which was copied to the folder in EC2 resource into RDS Postgres.

Navigating to the console, we should be able to monitor the status of the data pipeline task executions
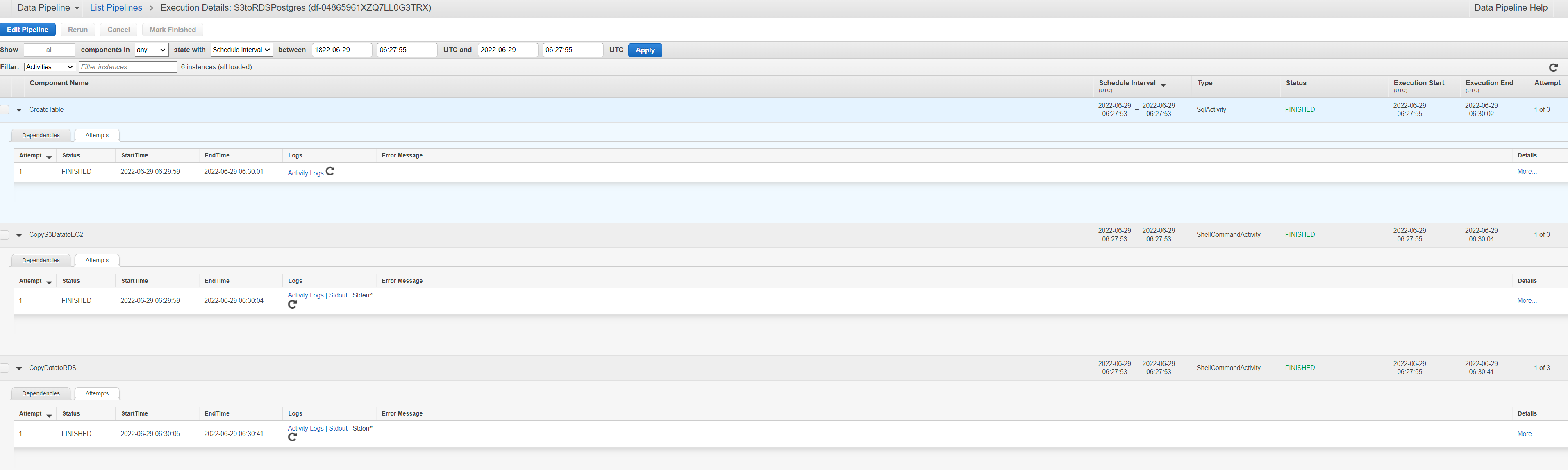
We can also diagnose failed executions from the logs in S3 in the location configured in pipeline definition s3://data-pipeline-logs1/logs/<pipeline-id>/ A sample of these logs is stored in data-pipelines/s3-to-rds/results_logs. These include the taskrunner in the ec2 resource and activity/stdout logs for the other activities (shell command and sql table create task activity)
One the pipeline has run successfully, we can check the data in Postgres RDS we can use PgAdmin and connect to the RDS server
- Create new server
- In the General tab, choose a server name e.g. RDSPostgres
- In the connection tab fill out the following details (which can be found in the configuration in the AWS RDS console)
- Endpoint/Host
- Port
- Username
- Password
- Click save and you should see the new server created in the browser window on the left
- Go to Tools -> Query tool. This should open up the query tool window.
- Run the command as in the screenshot below and you should see the data in the table if the data pipeline has run successfully
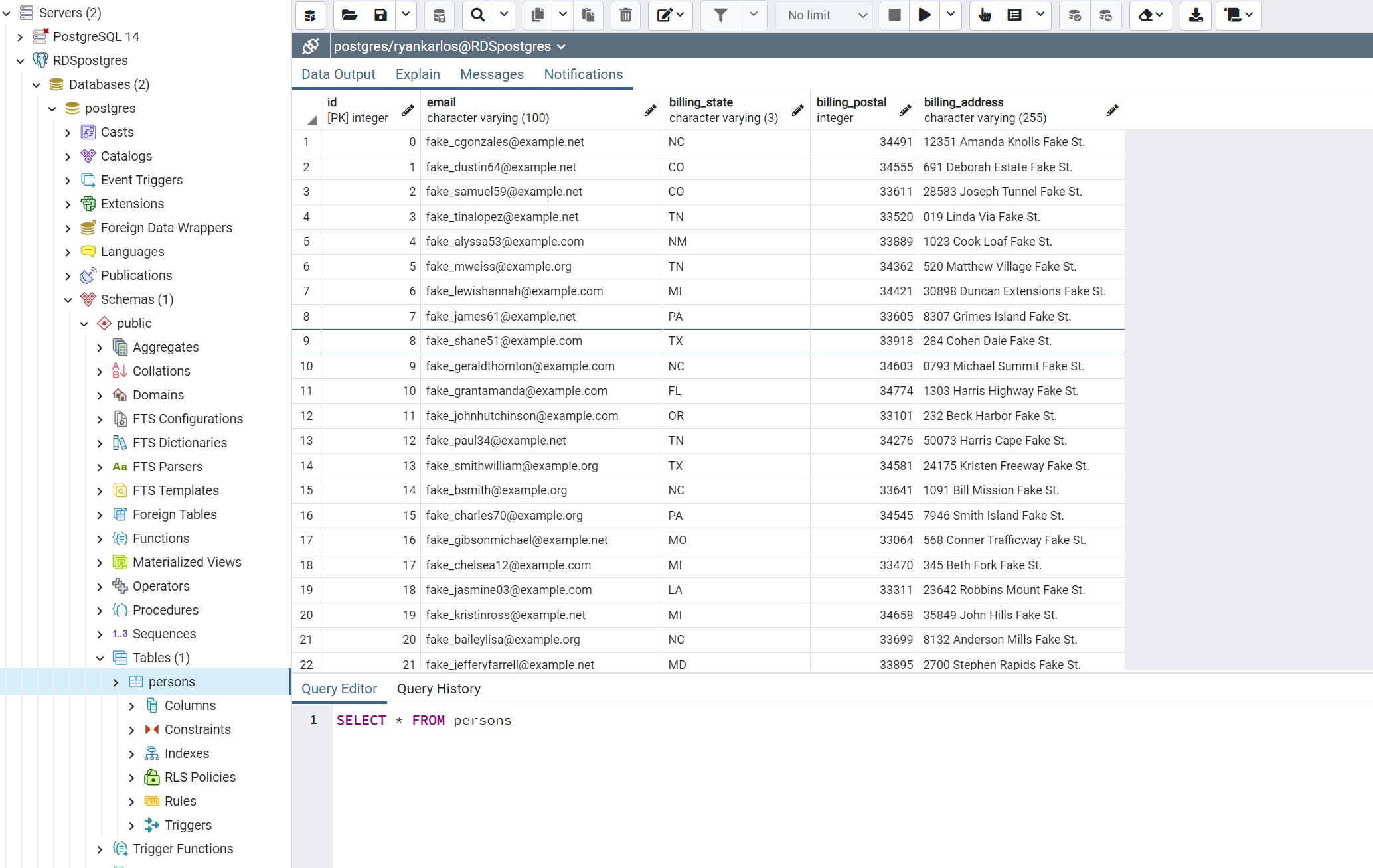
Once complete, delete all the resources to avoid unnecessary billing charges. Deleting the cloudformation stack for RDS will terminate the RDS instance.
s3 to s3
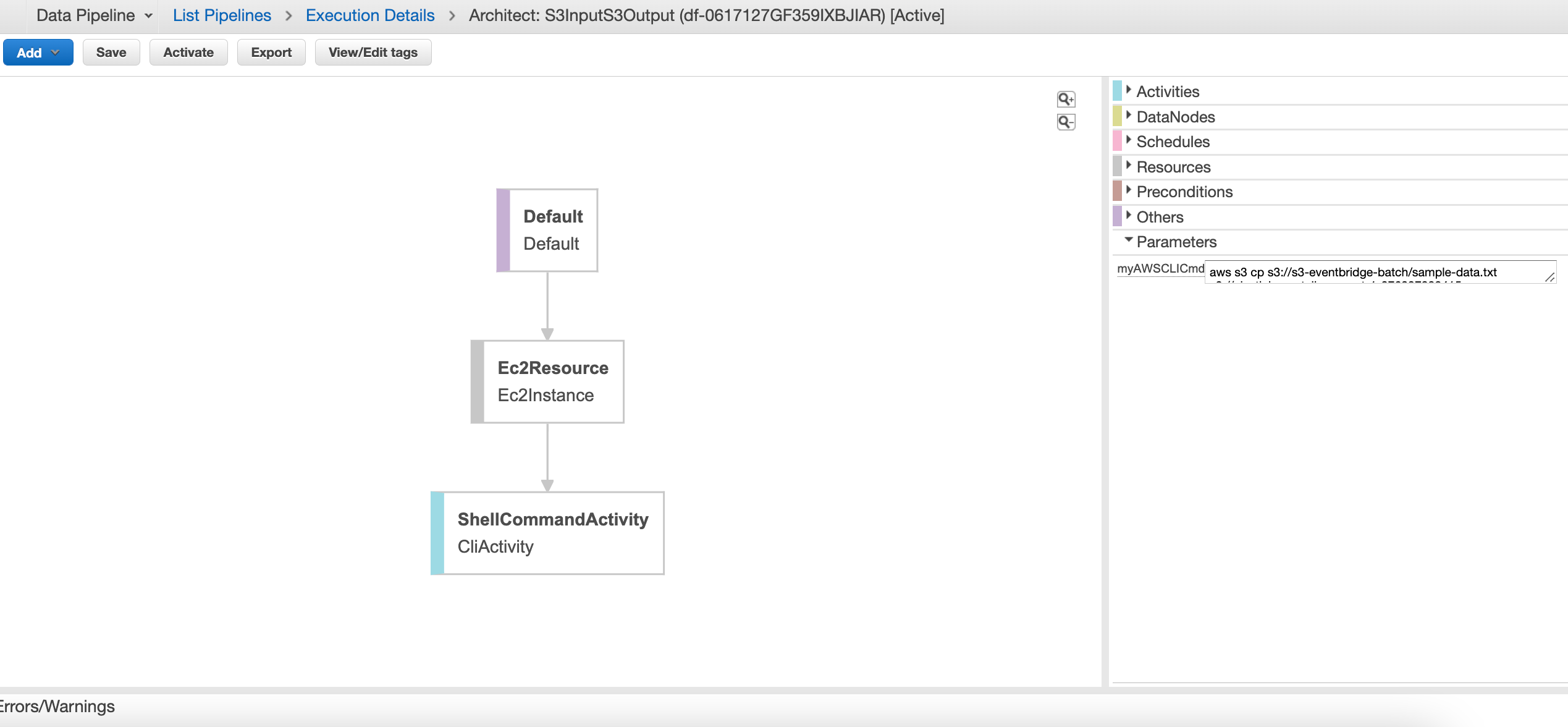
Run the cloudformation template stored in cloudformation/datapipeline/s3-to-s3.yaml to create stack using the cli command
1
2
3
4
5
$ aws cloudformation create-stack --stack-name DataPipelineS3toS3 \
--template-body file://cloudformation/datapipeline/s3-to-s3.yaml \
--parameters ParameterKey=InputPath,ParameterValue=s3://s3-eventbridge-batch/sample-data.txt \
ParameterKey=OutputPath,ParameterValue=s3://<bucket-name>
Navigate to the datapipeline console and click ion datapipeline id associated with the name used .e.g DataPipelineS3toS3 The pipeline should be activated and you can track the progress of the cli task Compared to the previous example, this is a lot more simplistic and just runs a shellcommand activity on the EC2 resource
s3 to Redshift
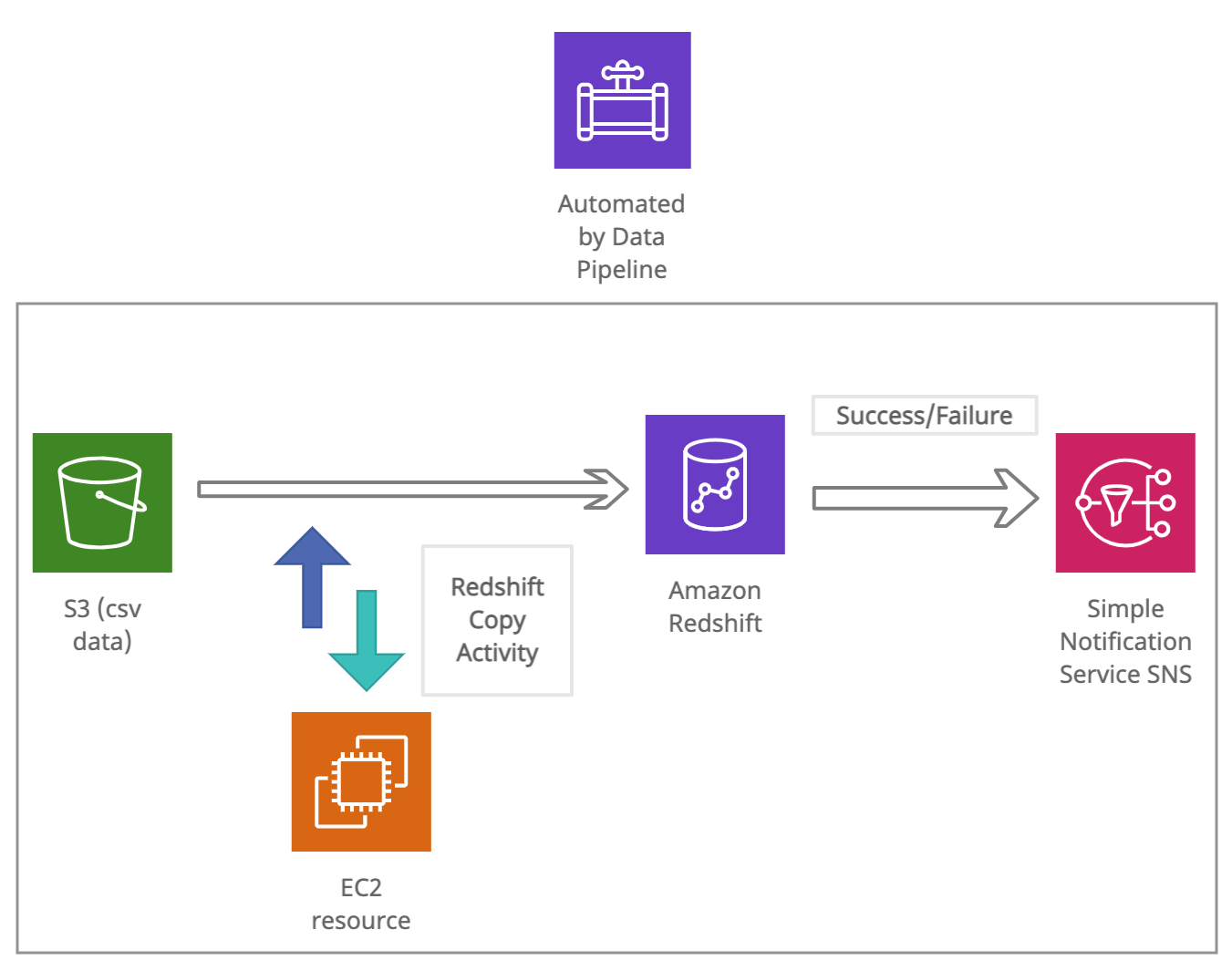
We have the datasets/delays.csv loaded in S3 bucket and we will use data pipeline to automate copying of this data into table in redshift cluster. To do this we first need to create and activate a redshift cluster
Creating redshift cluster
We can create a cluster ‘redshift-cluster’ with 2 nodes and default db ‘dev’ Also need to pass a list IAM roles that can be used by the cluster to access other Amazon Web Services services. Optionally can also pass vpc security groups to be associated with the cluster
1
2
3
4
5
6
7
8
9
aws redshift create-cluster --node-type dc2.large \
--number-of-nodes 1 \
--master-username user \
--master-user-password password \
--dbname dev \
--cluster-identifier redshift-cluster \
---iam-roles [<arn>/AWSServiceRoleForRedshift, <arn>/myspectrum_role]
--vpc-security-group-ids [sg-0f3936c13c90c635e, sg-2f8ca355]
--cluster-subnet-group-name default
Creating and updating pipeline definition
To create your pipeline definition and activate your pipeline, use the following create-pipeline command.
1
2
3
4
aws datapipeline create-pipeline --name flights_s3_to_redshift --unique-id token
{
"pipelineId": "df-002827213FORRFRNA4AT"
}
You can verify that your pipeline appears in the pipeline list using the following list-pipelines command.
1
2
3
4
5
6
7
8
9
10
11
12
13
$ aws datapipeline list-pipelines
{
"pipelineIdList": [
{
"id": "df-04133292K3OYT6A9KW89",
"name": "s3_to_dynamodb"
},
{
"id": "df-002827213FORRFRNA4AT",
"name": "flights_s3_to_redshift"
}
]
}
To upload your pipeline definition, use the following put-pipeline-definition command, with the pipeline id output from the commands above. The pipeline definition config json file is stored in data-pipelines/config/s3_to_redshift.json (this can also be generated once pipeline is created, using the get-pipeline-definition command
1
2
3
4
5
6
7
8
aws datapipeline put-pipeline-definition --pipeline-id df-002827213FORRFRNA4AT \
--pipeline-definition file://data-pipelines/config/s3_to_redshift.json
{
"validationErrors": [],
"validationWarnings": [],
"errored": false
}
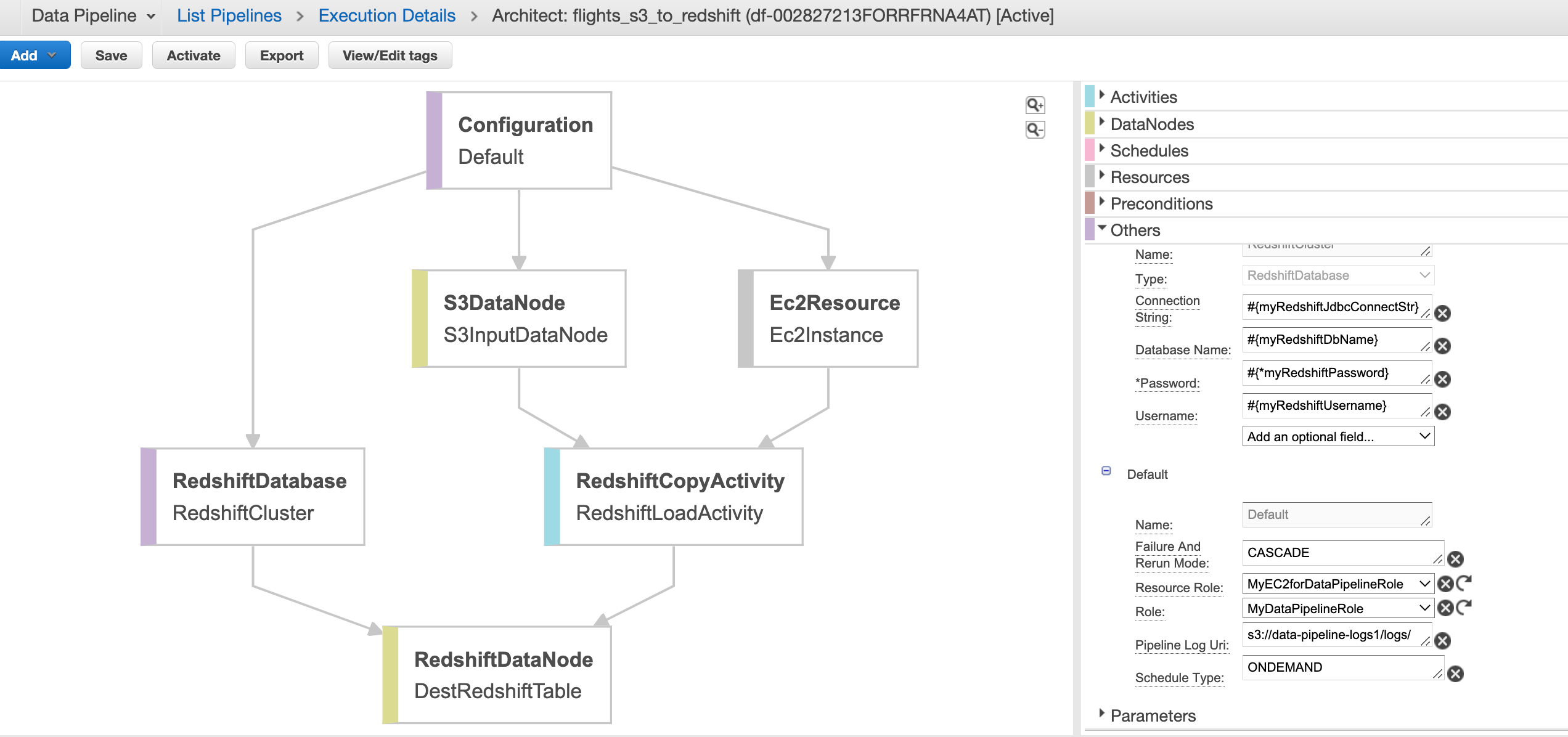
Activating pipeline and monitoring
To activate your pipeline, use the following activate-pipeline command.
1
aws datapipeline activate-pipeline --pipeline-id df-002827213FORRFRNA4AT
Monitor the pipeline run on the console or from the data pipeline logs folder in S3. These are partitioned by pipeline-id –> Activity_Type —-> Runtime —> Attempt_number e.g≥
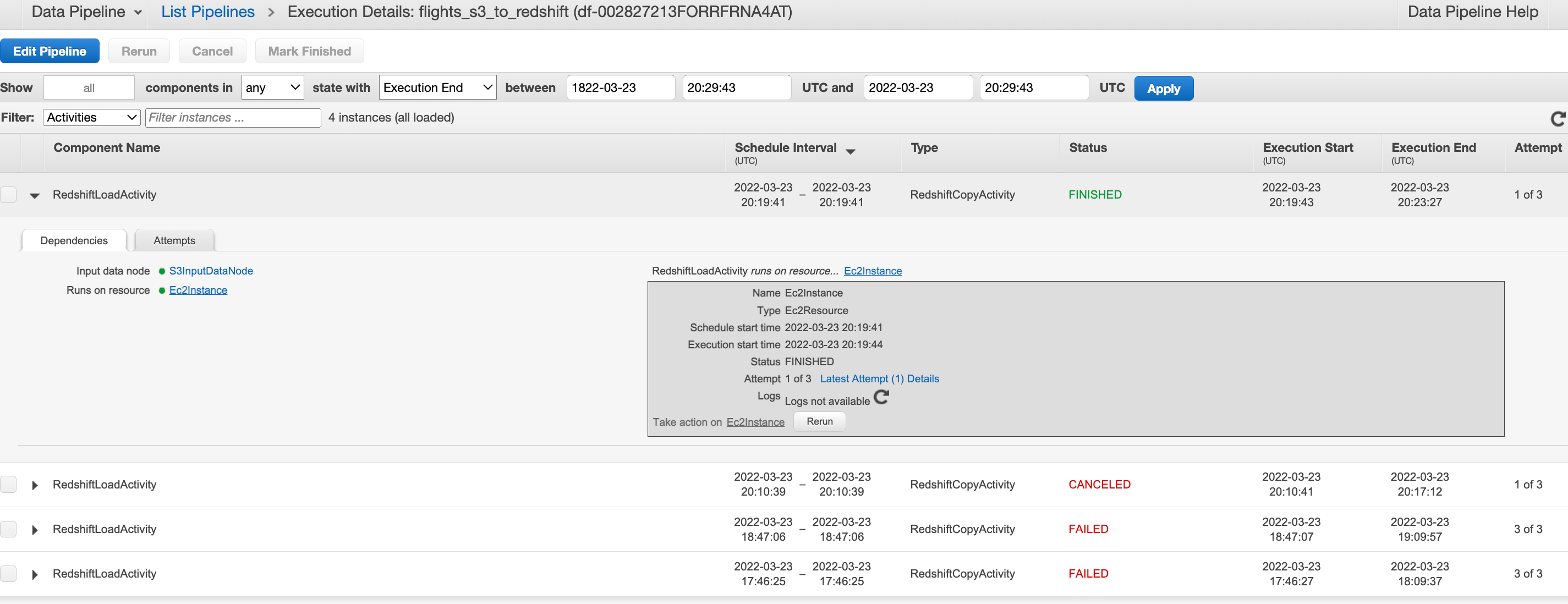
Comments powered by Disqus.